“从你的过去会话里学习”
OpenAI Codex 团队 5 月 25 日推送了一个新功能:从历史会话里自动抽取专属技能。X 用户 @shao__meng 把演示截图传上去,配文”Codex 现在会从你过去的对话里学习你的工作模式”。这条推文 24 小时内点赞 4.7 万、转发 1.1 万次,OpenAI 官方账号转发后又翻倍。
Distill Skills 的两种产物
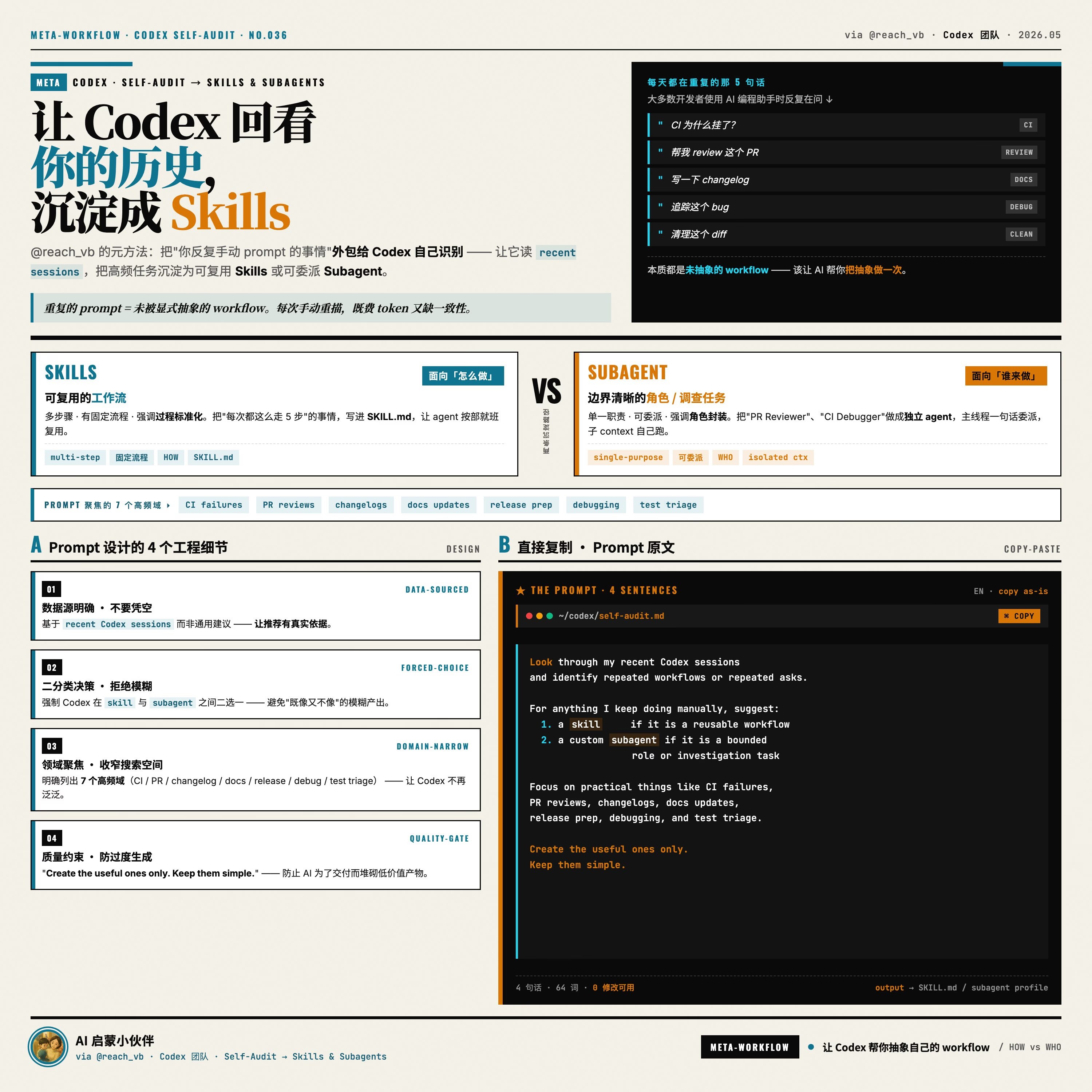
使用方式很直接。Codex 设置面板里点”Distill Skills from History”,勾选要分析的时间范围(默认过去 30 天),后端用一个分析模型扫一遍这段时间的对话,把高频且流程相似的任务归类成两种产物:流程技能(procedural skill)和独立代理(autonomous agent)。前者是一组固定步骤,触发关键词就跑;后者是一个有自己角色和工具集的子 agent。
OpenAI 在产品页给的内测数据:1200 名 Codex Pro 用户的 alpha 版本,每个用户平均蒸馏出 4.3 个 skill 和 1.7 个 agent,使用 14 天后日均触发次数 11.2 次——这个使用密度在 IDE 类 AI 功能里属于第一梯队。演示视频里给的例子是一位后端工程师过去 30 天有 27 次”创建 PostgreSQL 迁移文件”对话,被归类成 skill:输入”new migration <表名> <字段>“自动生成 .sql、写 down migration、跑本地测试。
把使用历史变成可挖掘资产
这件事的实质进步在”个人化”。Cursor、Claude Code、Codex 此前给所有用户的能力是平均化的,能力上限取决于模型本身。Skill distillation 让”使用历史”成为一类可挖掘的资产——一个用户用得越多,他的 Codex 就越懂他的代码风格、命名习惯、常用工具链。OpenAI Codex 产品负责人 Alexander Embiricos 在博客里写:”我们一直觉得 IDE 类 AI 工具的真正护城河不是模型本身,而是对单个用户的适配深度。”
底层技术不算特别新——OpenAI 用一个 reasoning 模型扫历史对话、聚类找模式、再用 fine-tune 或 prompt template 把模式固化。这套方法学术界叫 program induction,做了二十年。MIT CSAIL 的 Armando Solar-Lezama 教授在 X 上回应:”Program induction 主要卡在’用户怎么知道哪些操作值得固化’。OpenAI 这次让模型自己提议、用户审核——把学术问题降维成产品问题,做得不错。”
个人化沉淀就是工具锁定
隐私问题立刻被讨论了一轮。这个功能必须读你过去 30 天的对话,OpenAI 在产品页声明分析在账号隔离环境里跑、生成的 skill 不被用于训练全局模型。企业用户多了一个开关——管理员可以禁用整个团队的 distillation,避免商业代码细节被沉淀后被滥用。这是 OpenAI 在 Enterprise 版第一次把个人化功能做成默认 opt-out。
Cursor 的 changelog 里已经提到 “memory rules” 实验性功能,Aider 作者 Paul Gauthier 在 X 上回应”我们已经在做了,下个版本上”。个人化沉淀大概率成为 IDE 类 AI 工具下一阶段的竞争点。它的副作用是工具锁定——你的 skill 越多,迁移到别的工具成本越高。这条对用户是双刃剑,对厂商是护城河。
参考:X 推文演示


